Website Scraper is a powerful, web-based tool built to give you complete control over extracting data from any website. Whether you’re a developer, researcher, or business analyst, Website Scraper makes it easy to pull the exact information you need—quickly, efficiently, and without the usual roadblocks.
Key Features:
Extract using XPath selectors for precision targeting
Match text directly for fast, simple scraping
Pull data between two text values
Pull data between two HTML elements
Smart Crawling
Crawl only URLs containing specific values
Scrape only from selected URLs that meet your conditions
Start your scrape from any page, not just the homepage
Rotate user agents (browsers) to avoid detection
Use your own proxies for uninterrupted scraping
Run multiple concurrent connections to scrape faster
Filter results by successful and failed scrapes
See detailed error codes (401, 403, IP blocks, etc.)
Export scraped data in CSV format for spreadsheets, databases, or analysis tools
Why Choose Website Scraper?
Website Scraper is designed to save you time, eliminate frustration, and give you full flexibility over your scraping process. Instead of wasting hours coding your own scrapers or fighting against blocks, you can focus on what matters most—getting the data that drives your work.
Hi everyone, in this video we are going to show you how to use our website scraper tool.
So this is a tool that will scrape all the pages on any website and extract certain data from those pages. That can be things like prices or the website's titles—anything that you can reliably find within the HTML. And we'll go over how that works now.
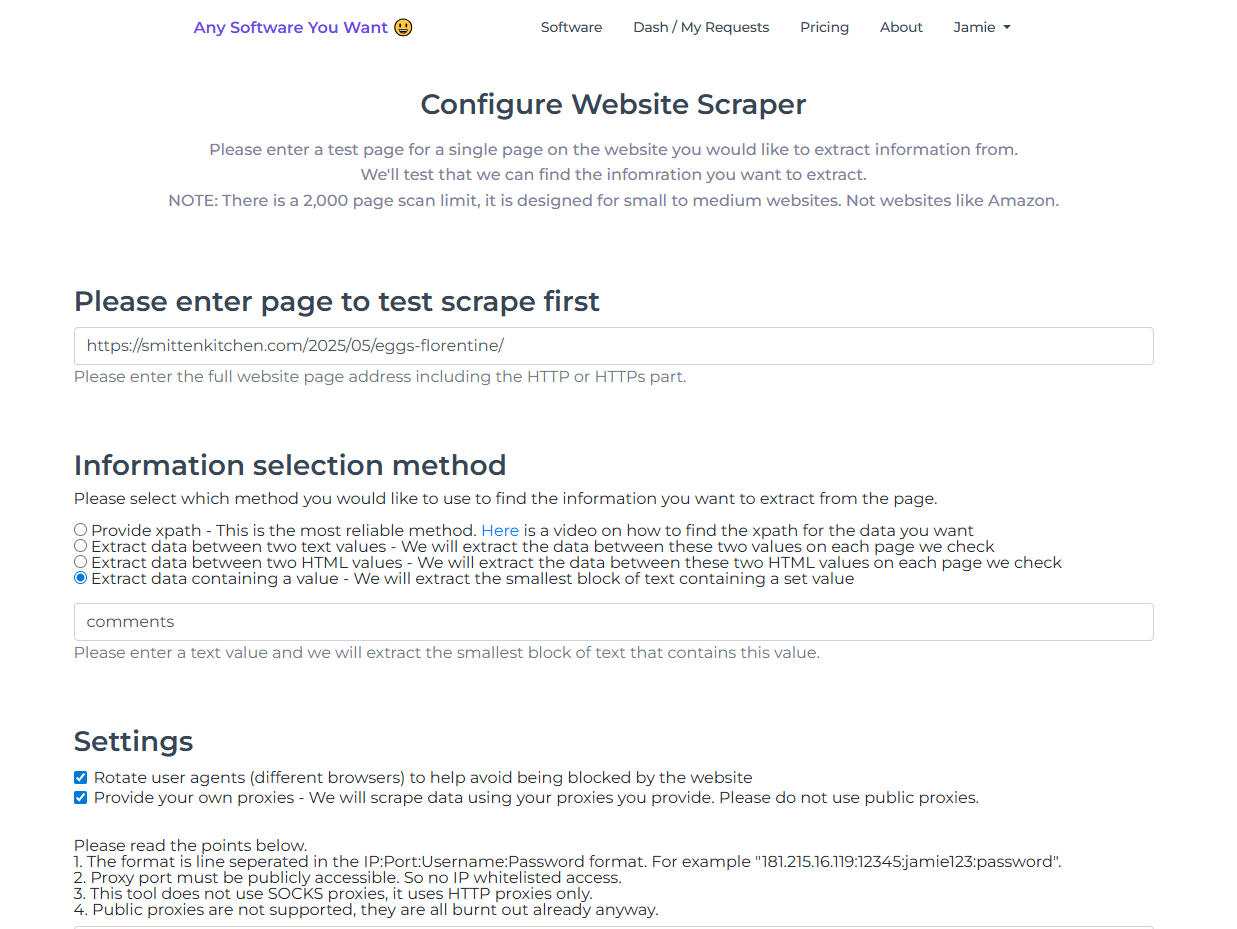
So obviously if you want to pull data from every page, the data needs to be structured in a predictable way. What that means is when we load each page, the data that you want needs to be in the same place within the HTML. The best way to test that is to enter a test page first.
You then provide a method for finding the data you want within the HTML, along with some other settings. You run a single page check, and if that passes, then you can crawl the entire website. We’ll go through all those aspects in detail now so you have a good understanding of how the tool works.
For our first example, I'm going to use XPath. XPath is a simple language for extracting data—basically for finding things within XML and HTML. It has its own syntax, but it's pretty straightforward to understand. What we're saying here is: find the first title tag within each page. We've set that as XPath, and there's a video here if you want to see how to find XPath for particular data within a page.
Now for the settings: you can rotate user agents. This is a piece of information your browser sends to a web server to tell it which browser is being used. Sometimes if you change browsers, you can send more requests to a website before it thinks you're sending too many requests from a single user. That means you can often scrape quicker if you rotate user agents.
If you're scraping a big website and want to do it quickly, but the site blocks attempts that come too fast, you can provide your own proxies here—we'll show that in another example shortly. We’ll keep this example simple for now.
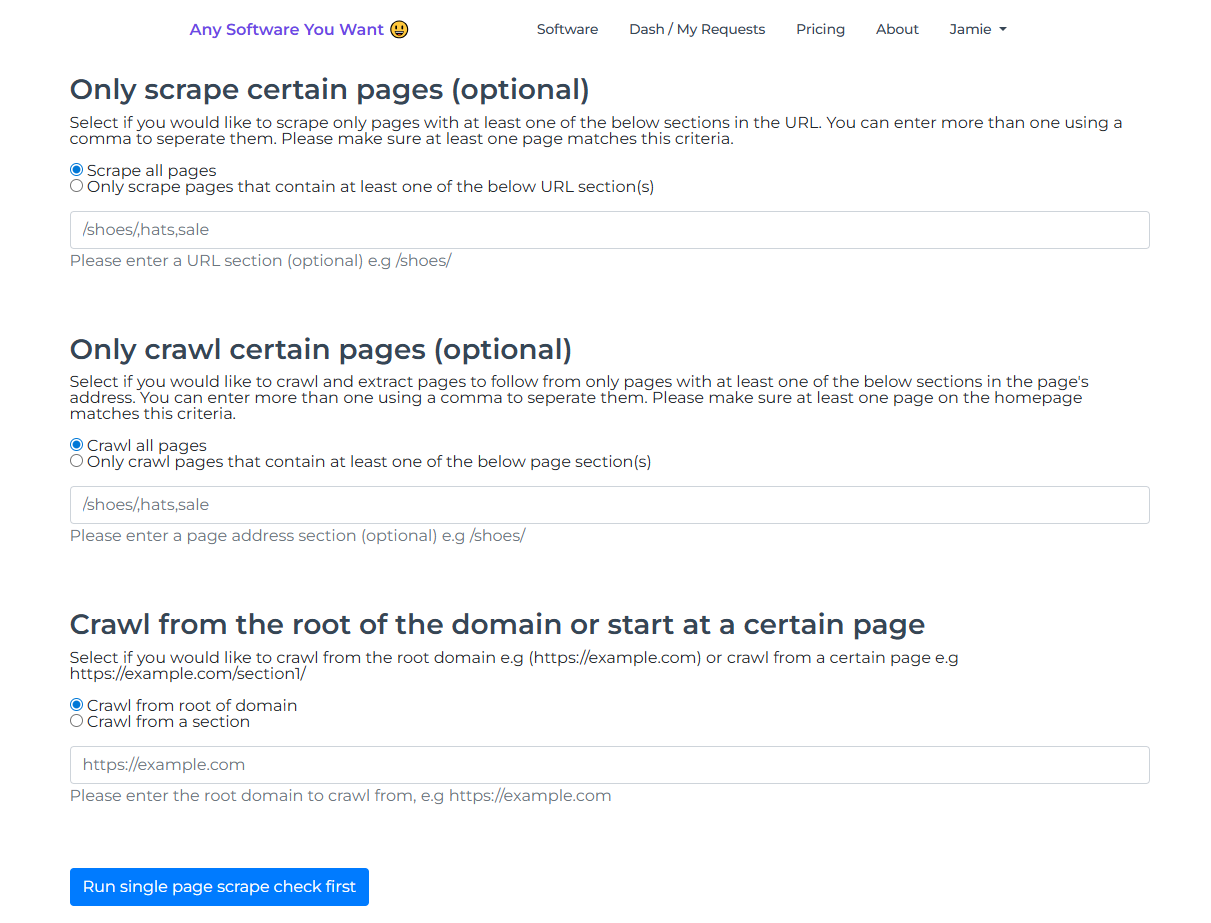
Next, you can choose to scrape only certain pages if you want. You can crawl all pages and then only pull data from pages that contain certain strings in the URL. You enter those as comma-separated values. If you want to only crawl certain pages, you can specify a string in the URL and we will only follow pages that match.
Finally, you may choose to start your crawl from the root of the domain (the home page) or from an inner page. For example, if you're scraping an e-commerce website and you only want the shoes, you might start at the top of the shoe category. If you're only crawling pages with “shoes” in the URL, you put that string in the filter and start from something like domain.com/shoes.
We'll keep it simple for the demo. We have our test page, our XPath to extract the title tag, no proxies, and we’re crawling from the root. Let's run a check. There you go—we've extracted the title tag from our test page.
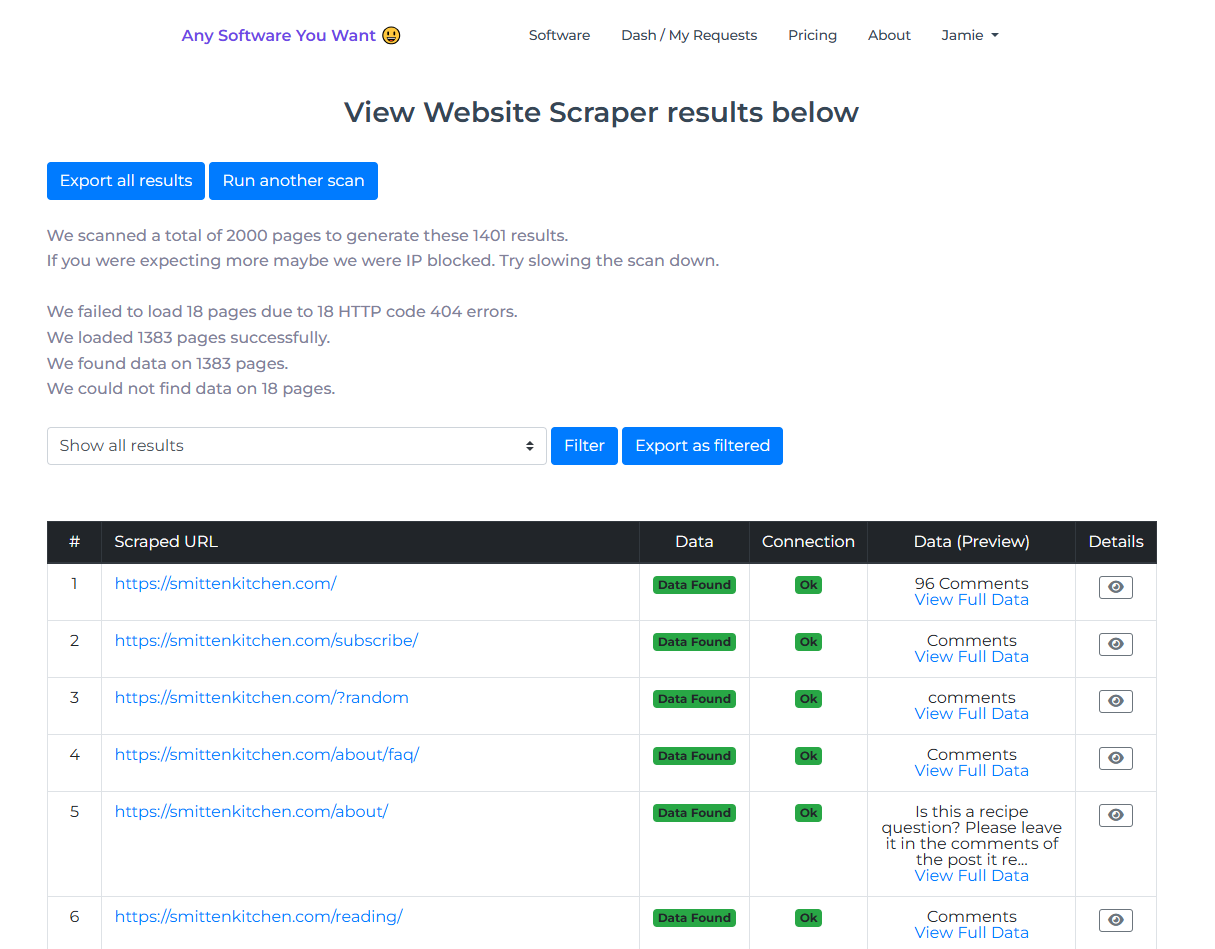
Now that we've confirmed it works, we can run a full website scan and extract that data from every single page. We'll kick that off now, and you can see it moving through every page on the website, extracting all the titles, and showing which pages were successfully scraped. Because every page has a title (it’s probably a WordPress site), we have a lot of successful extractions.
We come back a few minutes later, and we've gone through a couple of thousand pages. Here’s a brief overview: 19 pages failed to load out of 2000 because they returned 404 errors. Most pages loaded successfully, and we found the title tag on nearly all of them—1,981 pages found, 19 could not be found.
Looking at the results table, you see all the URLs we scanned, whether we found the data, whether the connection was okay, and a preview of the extracted data. If you click for full data, you see it in detail, and if you click for more details, you get information about what happened for that page.
Filtering for pages with issues shows the 19 pages that had errors. Clicking the details shows that they returned 404 errors, so we couldn't extract data.
That's a simple example of how you can extract titles from all of a website’s pages quickly. You can export the results as CSV.
Now let’s move on to something a bit more complex.
For our next check, we’ll use our own proxies. They must be in the specified format: IP or username/password. We’ll extract values between bits of HTML. For example, let’s extract our Google Analytics ID from each page. We enter the value, select the test page (the home page), choose to crawl from the root, and start.
After running the crawl, we come back less than a minute later. We crawled 112 pages, no blocks, and found the analytics ID on all pages. Clicking details shows more information about the page, including the title and which proxy was used.
That concludes this demo. Hopefully you can see it's a very simple and powerful tool. You enter your test page to understand the HTML, select a method for extracting data—XPath, values between text or HTML, or even the smallest block of text containing a certain keyword. This is useful when the HTML changes but the data always appears near a certain word or character.
You can add lots of proxies and move through a website quickly, extracting the data you need for your marketing activities.
That concludes the demo. As always, thank you for watching.
💬 Have a question or comment? Drop it below.
No comments yet — be the first!
Leave a comment